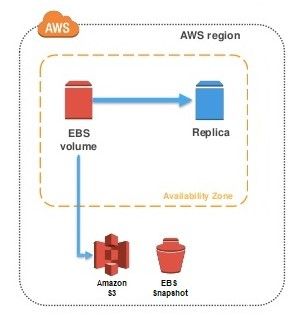
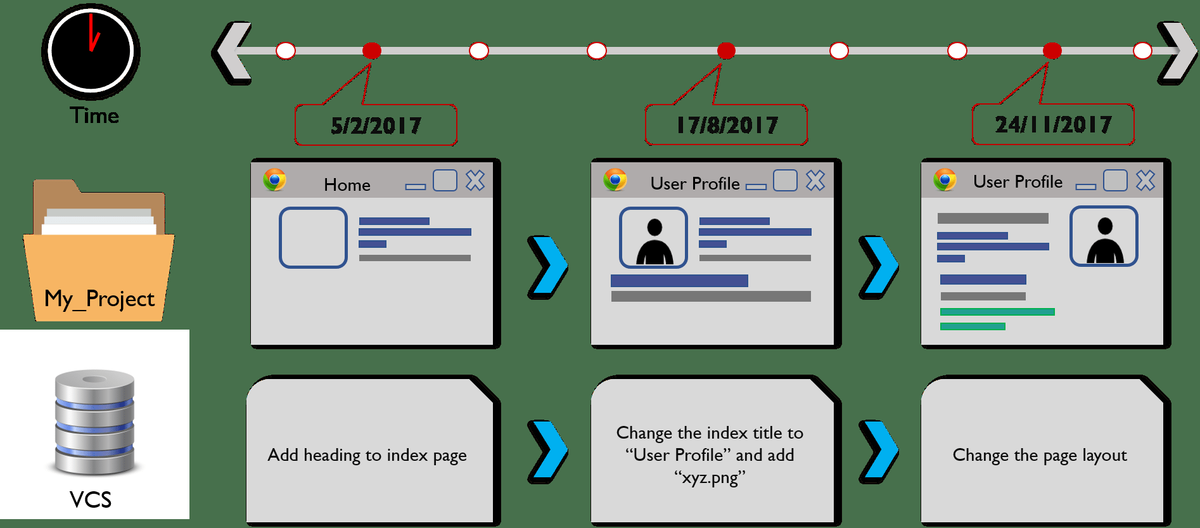
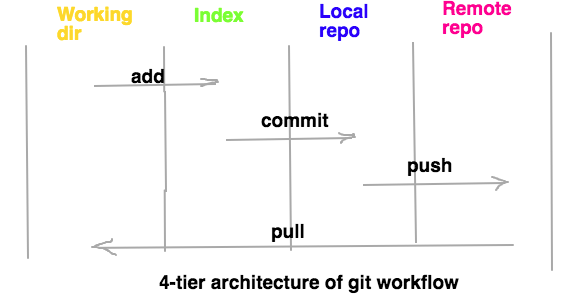
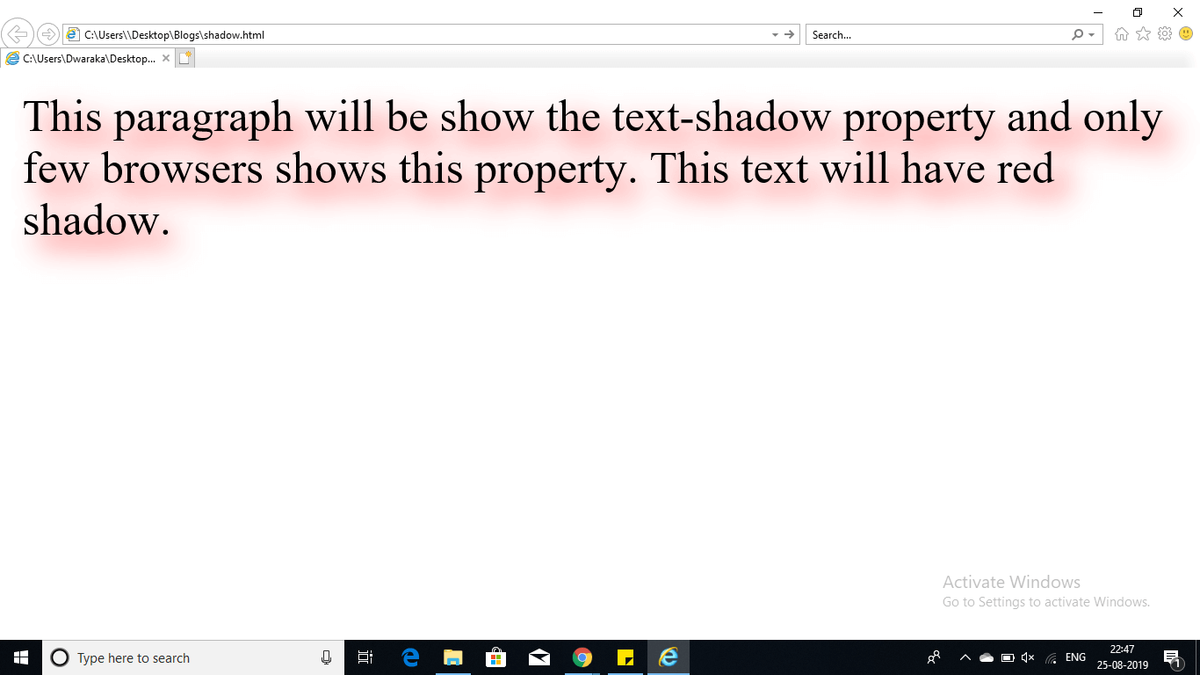
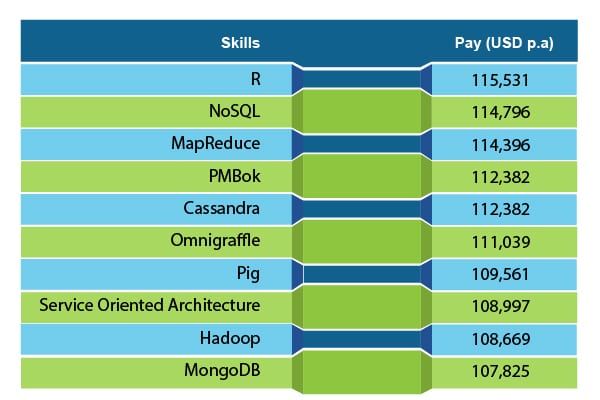
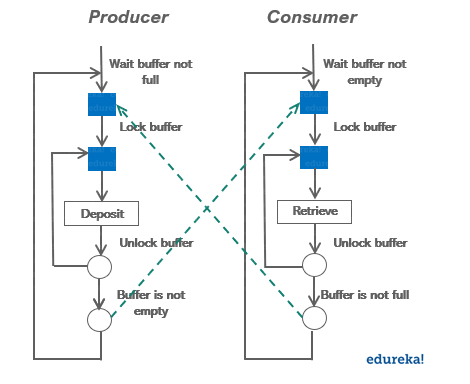
Hadoop administratora pienākumi
Šajā emuārā par Hadoop Admin pienākumiem ir apskatīta Hadoop administrēšanas joma. Hadoop administratora darbavietas ir ļoti pieprasītas, tāpēc mācieties Hadoop tūlīt!

Šajā emuārā par Hadoop Admin pienākumiem ir apskatīta Hadoop administrēšanas joma. Hadoop administratora darbavietas ir ļoti pieprasītas, tāpēc mācieties Hadoop tūlīt!
Apache Spark ir parādījies kā lieliska attīstība lielu datu apstrādē.
Apache Hadoop 2.x sastāv no būtiskiem uzlabojumiem salīdzinājumā ar Hadoop 1.x. Šajā emuārā tiek runāts par Hadoop 2.0 Cluster Architecture Federation un tās sastāvdaļām.
Tas dod ieskatu par Job tracker izmantošanu
Apache Pig ir vairākas iepriekš definētas funkcijas. Ziņa satur skaidras darbības, kā izveidot UDF Apache Pig. Šeit kodi ir rakstīti Java valodā un tiem ir nepieciešama Cūku bibliotēka
Tur HBase Storage arhitektūra sastāv no daudziem komponentiem. Apskatīsim šo komponentu funkcijas un zināsim, kā tiek rakstīti dati.
Apache Hive ir datu glabāšanas pakotne, kas izveidota virs Hadoop un tiek izmantota datu analīzei. Strops ir paredzēts lietotājiem, kuriem SQL ir ērti.
Apache Spark ar Hadoop ieviešana lielos uzņēmumos lielā mērā norāda uz tā panākumiem un potenciālu reāllaika apstrādē.
NameNode Augsta pieejamība ir viena no svarīgākajām Hadoop 2.0 funkcijām. NameNode Augsta pieejamība ar Quorum Journal Manager tiek izmantota, lai koplietotu rediģēšanas žurnālus starp aktīvajiem un gaidstāves nosaukuma mezgliem.
Hadoop izstrādātāja darba pienākumi ietver daudzus uzdevumus. Darba pienākumi ir atkarīgi no jūsu domēna / sektora. Šī loma ir līdzīga programmatūras izstrādātājam
Hive datu modeļos ir šādi komponenti, piemēram, datu bāzes, tabulas, starpsienas un kausi vai kopas. Strops atbalsta primitīvos veidus, piemēram, veselos skaitļus, pludiņus, dubultspēles un virknes.
Šie 4 iemesli jaunināšanai uz Hadoop 2.0 runā par Hadoop darba tirgu un to, kā tas var palīdzēt jums paātrināt karjeru, ļaujot jums atvērt milzīgas darba iespējas.
Šajā emuārā mēs darbosim stropu un dziju piemērus vietnē Spark. Pirmkārt, izveidojiet stropu un dziju uz Spark un pēc tam uz Spark varat palaist stropu un dziju piemērus.
Šī emuāra mērķis ir uzzināt, kā pārsūtīt datus no SQL datu bāzēm uz HDFS, kā pārsūtīt datus no SQL datu bāzēm uz NoSQL datu bāzēm.
Cloudera sertificētais Apache Hadoop (CCDH) izstrādātājs ir stimuls karjerai. Šajā amatā ir aplūkoti ieguvumi, eksāmenu modeļi, mācību ceļvedis un noderīgas atsauces.
Šajā emuārā ir sniegts pārskats par HDFS augstas pieejamības arhitektūru un to, kā vienkāršās darbībās iestatīt un konfigurēt HDFS augstas pieejamības kopu.
Apache Kafka joprojām ir populārs, runājot par reāllaika analīzi. Piedāvājam ieskatu tajā no karjeras viedokļa, apspriežot karjeras iespējas un darba prasības.
Apache Kafka nodrošina augstas caurlaidspējas un mērogojamas ziņojumapmaiņas sistēmas, padarot to populāru reāllaika analīzē. Uzziniet, kā Apache kafka apmācība var jums palīdzēt
Šis emuāra ziņojums ir dziļa iegremdēšanās Pig un tās funkcijās. Jūs atradīsit demonstrāciju par to, kā jūs varat strādāt ar Hadoop, izmantojot Pig bez atkarības no Java.
Šajā emuārā ir apspriesti priekšnosacījumi, lai apgūtu Hadoop, Java pamatinformāciju par Hadoop, un atbildes “vai jums ir nepieciešama Java, lai apgūtu Hadoop”, ja jūs zināt Pig, Hive, HDFS.